Reinforcement Learning
Reinforcement-Learning Benchmark Suite
An individual benchmark suite on algorithm choice, observation design, temporal context, and reward shaping.
Individual coursework benchmark suite · executed notebook figures published
01
Observe
Frame skipping and frame stacking
02
Configure
Policy and reward design
03
Train
Benchmark environments
04
Evaluate
Endpoint metrics and success conditions
AirRaid PPO
300 → 1,925
Verified mean-reward endpoints after temporal observation changes.
MountainCar
100%
Final success rate under the shaped-reward evaluation.
Executed reinforcement-learning evaluation
The gallery includes exported curves from the submitted notebook.
Scope
Role and problem
My role: Implemented and compared agents, preprocessing choices, reward wrappers, evaluation callbacks, and exported learning curves.
Control performance depends on more than selecting an algorithm. Observation design, temporal context, and reward structure materially change what an agent can learn.
Architecture
System flow
Taxi-v3 Q-learning
LunarLander DQN and PPO
AirRaid pixel observations
Frame skipping
Frame stacking
MountainCar reward wrappers
Training-curve analysis
Evidence
Measured signals
300 → 1,925
AirRaid PPO mean reward
Executed comparison between no-skip/no-stack and skip=6, stack=3 preprocessing.
100%
Final MountainCar success rate
Executed momentum-position reward-shaping evaluation.
Q-learning · DQN · PPO
Algorithm comparison
Compared discrete, control, and pixel-based learning workflows.
Published Evidence
Selected artifacts.
Charts, screenshots, and media artifacts supporting this case study.
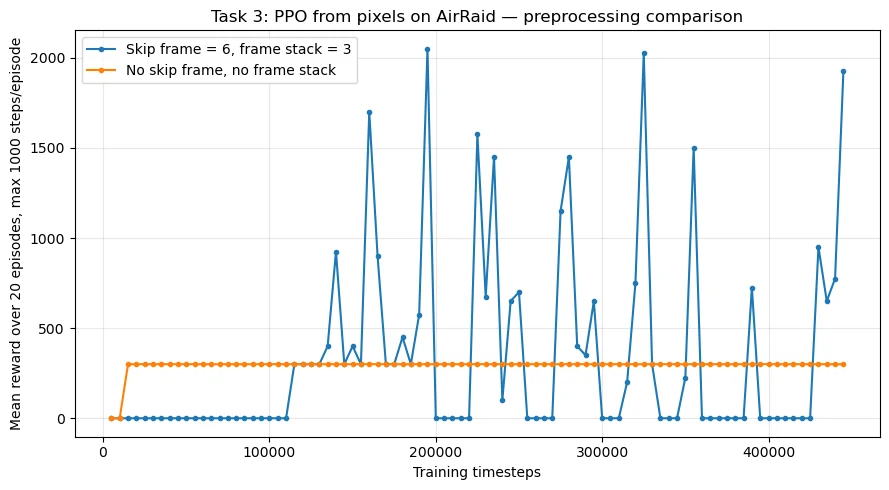
image evidence
AirRaid PPO preprocessing comparison
Exported from the executed notebook: AirRaid reward trajectory comparing skip=6, stack=3 against no-skip/no-stack preprocessing.
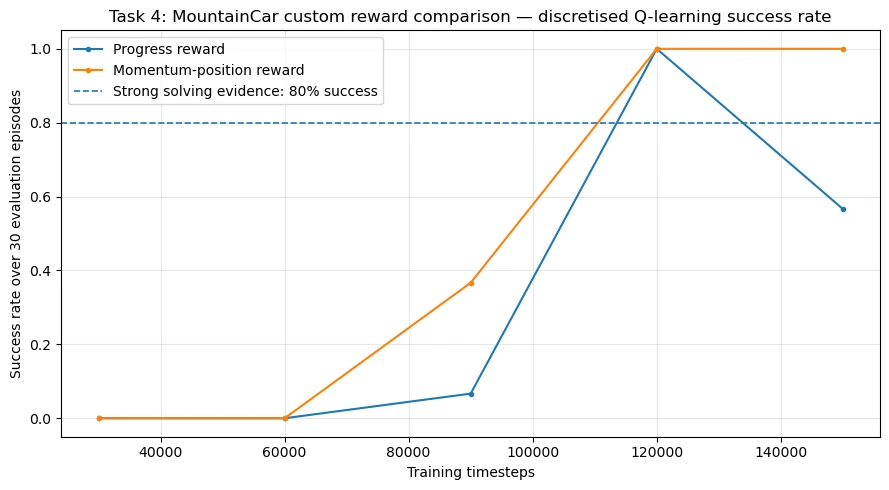
image evidence
MountainCar reward-shaping success rate
Exported from the executed notebook: success rate across evaluation checkpoints for the two shaped-reward designs.
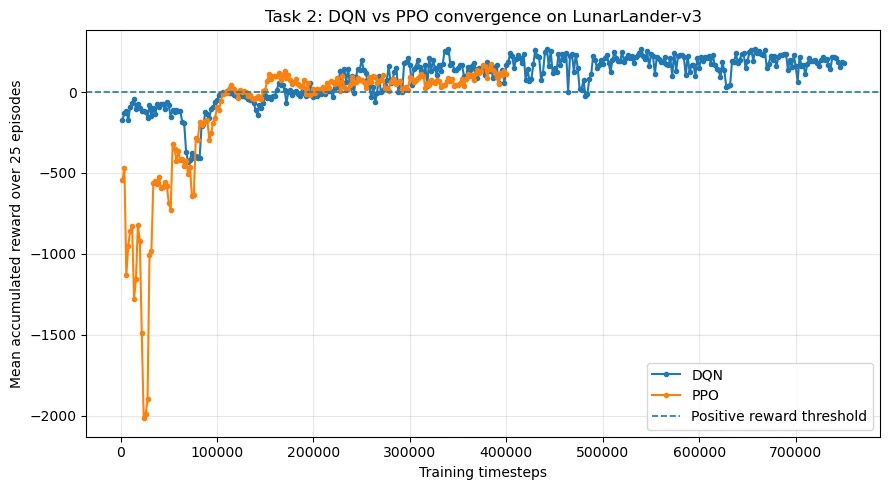
image evidence
LunarLander DQN and PPO comparison
Exported from the executed notebook: mean-reward trajectories for DQN and PPO on LunarLander-v3.
Contribution
- Implemented benchmark agents across four environment families.
- Changed temporal observation design through frame skipping and stacking.
- Designed and evaluated custom MountainCar reward wrappers for sparse-reward learning.
Lessons
- Observation design can matter as much as algorithm choice.
- Reward shaping is an interface-design problem, not a shortcut.
- Executed curves make the experimental path inspectable instead of relying on endpoint claims alone.
Limitations
- The public figures are exported from the executed coursework notebook.
- Results are scoped to the stated benchmark environments and evaluation settings.
- The notebook evaluates single executed runs rather than a multi-seed research benchmark.
Stack
- Python
- Gymnasium
- Stable-Baselines3
- Q-learning
- DQN
- PPO