NLP · Semantic Retrieval
RedditPulse: Semantic Retrieval and Grounded Insight Platform
A collaborative NLP and retrieval case study on measuring semantic-search quality before treating generated insights as useful.
Collaborative academic prototype · verified evaluation outputs
Precision@5
0.68
Recall@5
0.68
Embedding size
384d
Verified retrieval metrics
Measured evaluation results from the collaborative prototype.
Scope
Role and problem
My role: Collaborative academic project. My portfolio presents the retrieval evaluation, dashboard workflow, and public evidence with explicit team attribution.
Public discussions are noisy, high-volume, and difficult to inspect with keyword search alone. The system needed an evidence-first retrieval layer before generated summaries could be treated as useful.
Architecture
System flow
Reddit collection
Text cleaning and metadata
Sentiment analysis
Topic detection
Sentence-transformer embeddings
FAISS retrieval
Top-k evaluation
Grounded insights
Streamlit dashboard
Evidence
Measured signals
1,989
Filtered posts
Collaborative dataset after collection and filtering.
1,588
Comments
Discussion context across 10 subreddits.
P@5 = 0.68 · R@5 = 0.68
Semantic retrieval quality
Verified top-five evaluation using 384-dimensional embeddings and FAISS.
Published Evidence
Selected artifacts.
Charts, screenshots, and media artifacts supporting this case study.
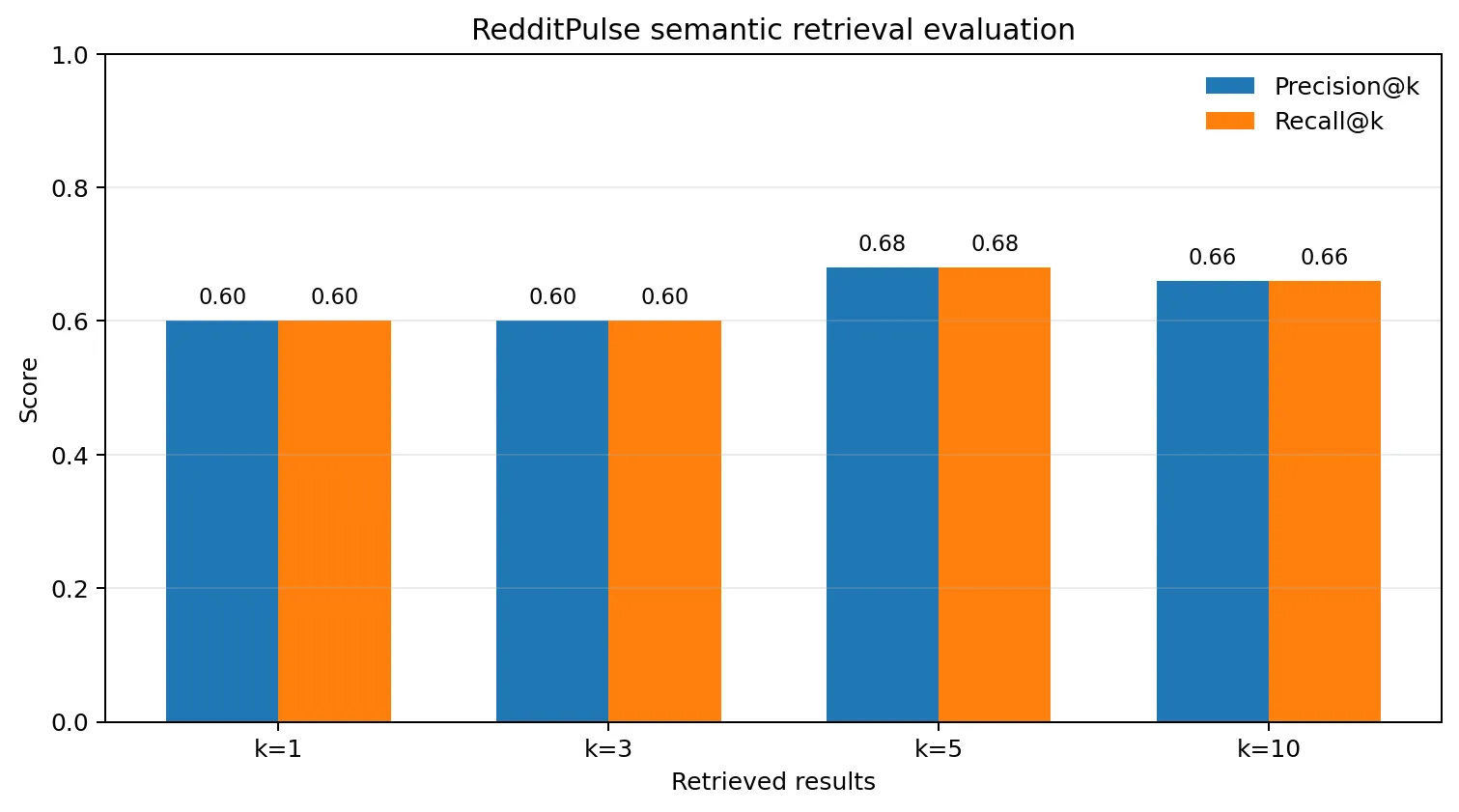
image evidence
Semantic retrieval evaluation
Generated from the project evaluation JSON: Precision@k and Recall@k across the published retrieval cut-offs.
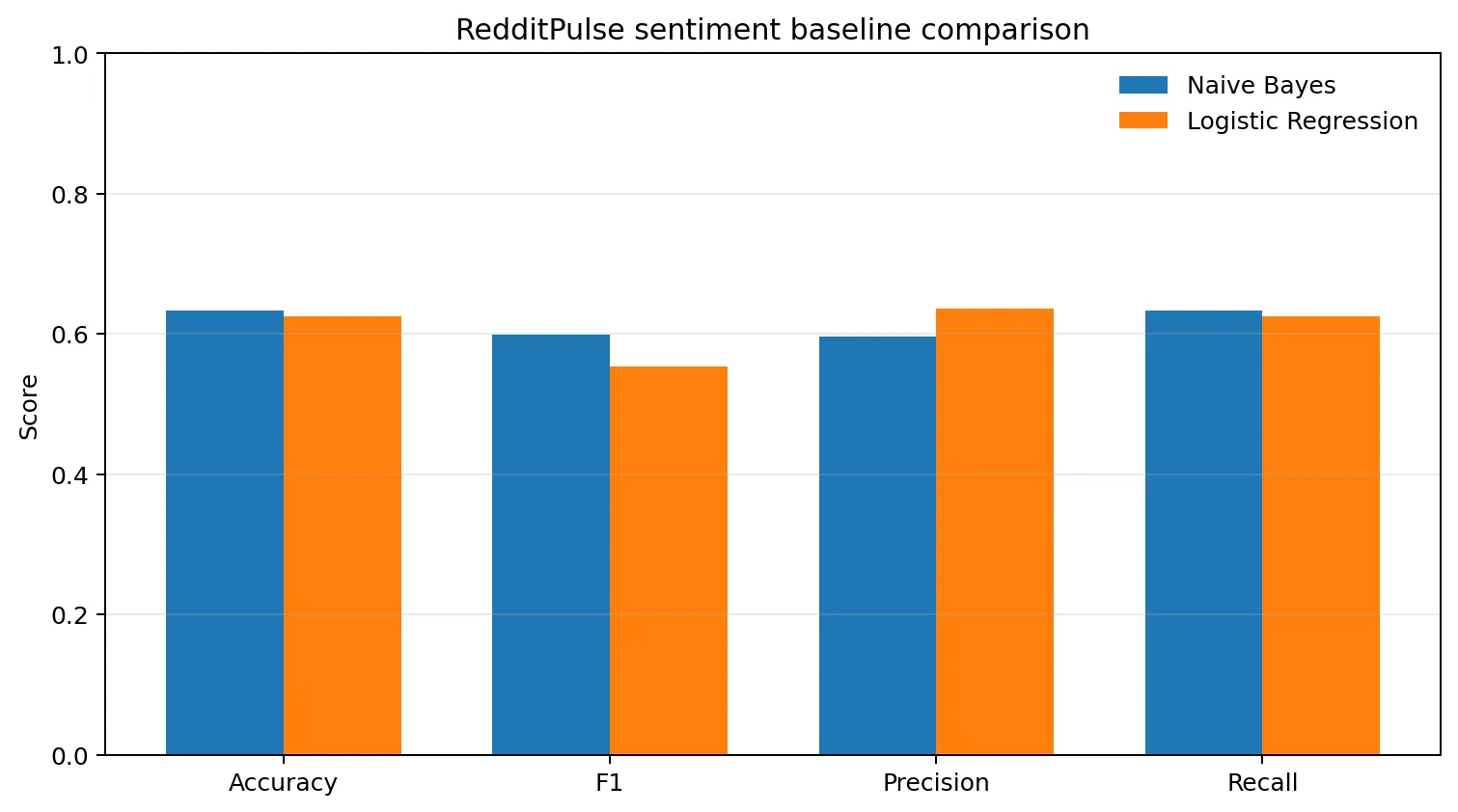
image evidence
Sentiment baseline comparison
Generated from the project evaluation JSON: Naive Bayes and Logistic Regression baseline metrics.
Contribution
- Contributed to the collaborative platform and document the retrieval-evaluation path, public metrics, and dashboard workflow.
- Keep generated insight claims grounded in measured retrieval quality.
- Present the team-level prototype with explicit collaborative attribution.
Lessons
- Retrieval quality should be evaluated before generation is celebrated.
- TF-IDF remains a valuable baseline even when dense retrieval is added.
- Interactive interfaces are most useful when they expose retrieval context, not only generated summaries.
Limitations
- The metrics and evaluation charts describe the collaborative academic prototype.
- A public Streamlit URL can be enabled from the central content file after deployment.
- The dashboard is a research prototype rather than a production service.
Stack
- Python
- NLP
- RoBERTa
- Sentence Transformers
- FAISS
- RAG
- Streamlit